Getting started with Couchbase
After having a quick glance to MongoDB in my previous articles, I decided to compare it to another document store. First, I wanted to look at CouchDB, but I rapidly discovered that the founder of CouchBase has developed another product named Couchbase Server which expanded the key-value store Membase with lots of concept used in the docstore CouchDB. So Couchbase Server is not only a document store but rather a key-value store that support queries like in document stores so that you can find and aggregate your values based on their attributes. Another important concept behind Couchbase is that it was build to run on multiple nodes, supporting both partitioning and replication.
The main idea behind key-value stores is that every entry has a unique key with which you have a fast access to the document. The key is at max 250 bytes long and is NOT auto-generated by the system like in lots of other databases. As value you can theoretically store anything: binary, text or JSON documents. For values not stored as JSON, they can only be queried using the key, so if you want to benefit from the document store capabilities of Couchbase you need to store the documents in JSON format.
The base of Couchbase is open source and there are the paid Enterprise and the free Community Edition that are based on it. On the Couchbase Homepage you can find instructions on how to install using Docker and how to install directly. The Enterprise Edition gets the bug fixes faster, includes support and some advanced features not available in the Community Edition (e.g. monitoring tools and advanced tools for backups).
After installing Couchbase Server on one (or more machines), you need to open the web console at
Here we come to one of the differences between MongoDB and Couchbase: while in MongoDB there were two layers on how to separate your data (databases and collections), in Couchbase there is only one: buckets. When you create a bucket, you have to decide of the type of the buckets, there are three possibilities:
- Couchbase: use it if you want to persist your data on the disk. Will have all querying possibilies
- Ephemeral: data will be in-memory only, so as soon as the server stops or the data has to be ejected from RAM, it is gone. You can do ad-hoc queries like on a Couchbase bucket, but views (we’ll come to this later) are not supported
- Memcached: in-memory bucket that supports only key-value operations and value sizes of max 1MB (vs 20MB in the other bucket types). Usually used as cache for other data stores like relational databases
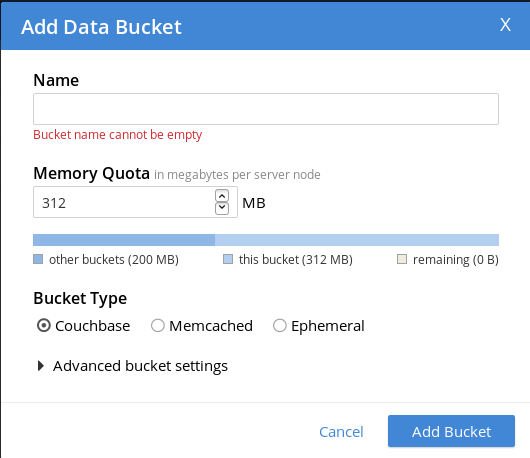
So if you want to use Couchbase as a persistent database, you have to use a Couchbase bucket, if you only want to store some temporary data like user session data without persisting it, you can use one of the other two. For now, we will use a Couchbase bucket, to demonstrate the query possibilities you have with Couchbase. You can store all kind of documents in a bucket, so if you want to narrow them down, you can add a type attribute to your documents so that you easily determine what is stored in the document.
There are three ways to query in Couchbase: accessing using the key, using index views or using the N1QL (pronounced nickel) query language.
The first option is pretty simple: you can either retrieve a document directly by its key or all the documents within a range of keys. If you want to do further narrow down your documents based on the values you would have to do it in your application code. You can try this out by selecting a bucket in the Buckets section of your Couchbase console.
The second option is creating an index view. To do this, you click on Indexes in the side menu and then on Views in the top menu. Then you can create development views.
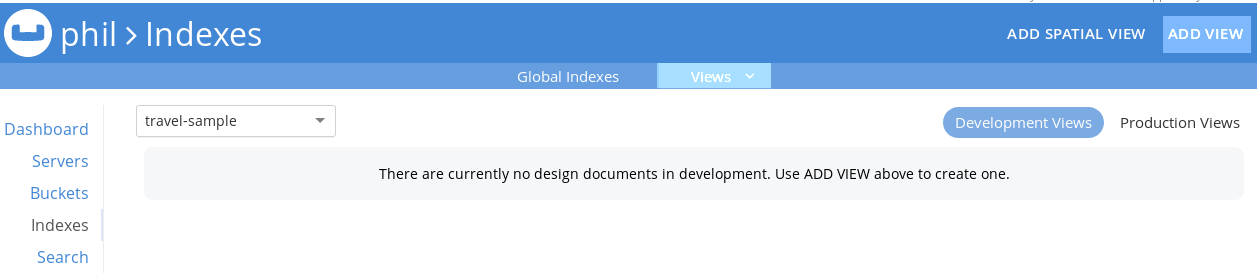 To do this, you first need to create a design document which can then contain multiple views that can only be published together. So don’t put views in the same design document, if you want to be able to publish them independently.
To do this, you first need to create a design document which can then contain multiple views that can only be published together. So don’t put views in the same design document, if you want to be able to publish them independently.
Then you have to enter your map function which has the following format:
func (doc, meta) {
// code to adapt
emit(key, value)
}You have doc and meta as parameters: doc is your document, so you can access the attributes of your documents via this parameter and meta contains the metainformation so mainly the id and the expiry. The function will be applied to all documents and each call to emit will return a result. Every result document then has the following form:
{
"id": ...,
"key": ...,
"value": ...
}So every result you emitted will contain the id of the document as well as the key (first argument of emit) and value (second argument of emit). As the id is provided automatically, there is no need to pass anything as value, if you want to retrieve the whole document or only the id. You can later access the whole document efficiently as you have the id (when you query the view using the SDK of your programming language, you will be able to retrieve the whole document directly with one method call on the result object). Of course, if you want to access only small parts of the document, e.g. the e-mail address of a user, you can add it as value. You won’t need to acess the full document later to retrieve it if this is all you needed.
If you want to do further operations on all results with the same key, you can use the reduce function. There you can specify how to aggregate all values with the same key to one single result for this key (e.g. build a sum or put them all in a list).
Now comes the special thing about these views: as soon as you publish them, they don’t need to be evaluated every time you access them, but they are calculated once and then kept in memory. Every time the bucket is changed, the view needs to be updated as well. This is handled by the Couchbase server. Depending if it is okay for the view to show old data to the user, there are three configuration options, which you can set using the stale parameter:
- update_after: the view is recalculated after each view access
- stale ok: the server will return the current status of the view, the user may see old results
- stale false: the server will only return the view to the user, once it is up to date
So opposed to ad-hoc queries that you have in MongoDB, view queries are pre-computed and apart from filtering on the keys you want to retrieve from the views, nothing has to be computed at query time. So index views are a good way to save queries that are part of your main workload and that are executed very often.
Note that only Production Views are precalculated, so when you are done developing a view, you need to publish your development views. This can be done in the Indexes menu.
As you sometimes also want to do some ad-hoc queries on documents, there is also a possibility included in Couchbase Server to to this. This is the N1QL query language which I have handled in my next post.